Sequences of purchases in credit card data reveal lifestyles in urban populations
Contents
Paper
- Title: Sequences of purchases in credit card data reveal lifestyles in urban populations
- Authors: Riccardo Di Clemente, Miguel Luengo-Oroz, Matias Travizano, Sharon Xu, Bapu Vaitla & Marta C. González
- DOI: 10.1038/s41467-018-05690-8
- Tags:
- Year: 2018
- Open Access: Yes
Notes
What
- A framework was defined using a text compression technique on the sequences of credit card purchases to cluster different patterns of collective behaviors. Five consumer groups which shared similar characteristics were found. If deconstruct the transaction data properly with Zipf-like distributions, this method will uncover sets of significant sequences that reveal insights on collective human behavior.
Why
- We leave digital traces of our daily activities. e.g. people we call, places we visit.
- Properly analyzing digital traces can help build a framework which improve our society in different fields. e.g. Call detailed records (CDRs) were used to predict human mobility.
- Credit card records (CCRs) not only helpful to measure similarity in purchases and detect human mobility, but also helpful to uncover collective behavioral information of consumers.
How
- Data characteristic
- Daily purchase data follows Zipf distribution, meaning that the most frequent category of purchases will occur approximately twice as often as the second most frequency category, three times as often as the third, etc. e.g. 1st - food, 2nd - mobility, 3rd - communication-social activities.
- Grouping consumers depending on their socio-demographic attributes preserves the Zipf-like behavior and dominant purchase (food). Each group has its special order of frequent categories which relies on socio-demographic features such as income, gender and age.
- Challeges & Solutions
- Highly uneven distributed data
- Solution 1 : Similar to analyze the sequence of diseases in medical records or phenotype associations with diseases. Frequency-inverse document frequency (TF-IDF) ranking is used to eliminate redundant information.
- Solution 2 : Process uneven word frequency in the text corpora. Bayesian inference methods detect hidden semantic structure and latent Dirichlet allocation (LDA) finds the best summaries of documents.
- Proposed solution : Considering temporal order, identify significantly ordered sequences of transactions and cluster similar users.
- How to use CCRs to detect spending habits
- Solution : Combine CCRs, demographic information and mobile phone records.
- Deconstruct Zipf-like distributions and separate behaviorial groups
- Extract significant sequences from labeled data with Zipf-like distribution.
- Capture semantic of spending activities from CCRs.
- Combine information extracted from CCRs, mobile phone data and demographic information to group customers.
- Five groups which are similar in age, gender, expenditure, mobility and social network diversity were detected.
- Highly uneven distributed data
Results
- Data Analysis
- Individual CCR transactions
- Range: over 10 weeks in 150,000 users who live in Mexico City.
- Attributes: age, gender, Merchant Category Code (MCC)
- CDR
- Range: 6 months (overlapping CCR period), 1⁄10 users of CCR’s
- The adoption of credit cards predominantly occurs among users with higher wages in each district. (Correlation between median CCR expenditure & average monthly wage → high in car users)
- Male and young adults are the majority of credit card holder.
- Frequency of purchase types follow Zipf-like distribution.
- The frequency varies in different wealth, age and gender.
- Dominant categories are food, mobility and communication and in that order.
- Individual CCR transactions
- Credit card transaction codes as sequence of words
- Transform temporal sequence of user MCC codes into a sequence of predefined symbols.
- Use Sequitur algorithm to generate words that consist of several high frequency MCC symbols occurs in sequence. More than 10,000 words that follow Zipf-like Law are generated. The criteria is z-score threshold.
- The lifestyles
- How
- Decompose each significant word as direct links between its transaction codes. And each user is represented by a directed network which contains all possible significant direct links.
- Calculate Jaccard similarity coefficient between all users to compare their similarity and obtain shopping similarity matrix M.
- Group users in matrix M using a parallel Louvain algorithm.
- User groups
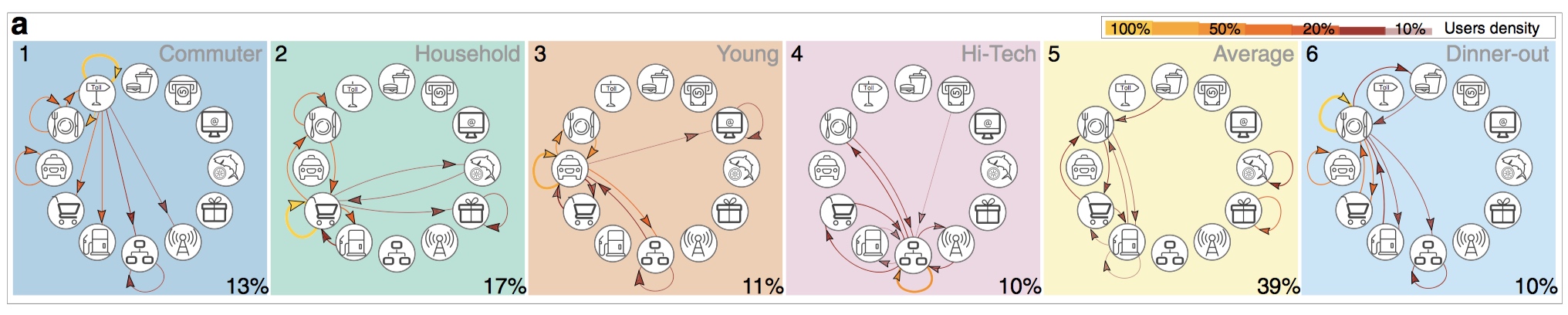
- Six groups: average, commuter, household, young, hi-tech and dinner-out.
- How
- Coupling credit card data with mobile phone data (Analyze user’s social contacts and mobility network)
- Social network diversity: Entropy, related to $ \text{user’s communication events with reciprocal contacts} / \text{num of contacts}$
- Homophily: Metric, investigate whether or not users in the same group contact each other more often
- Mobility diversity: Entropy, in normalized number of trips between locations
- Radius of gyration: The radius of circle which contains the most likely places to find the user. Centered in all visited locations and weighted by visited times.
- Mobility: Investigate phone activities in a region (specifically, the cell towers’ residual activity) and analyze the proportion of returners and explorers.
Discussion
- One transaction type is the core type in each group and it’s repeated by 90% users within the cluster.
- User groups
- Cluster 5 - Average: Uncategorized users. Users have less than 5 significant sequences and less variation in their expenditure types.
- Cluster 1 - Commuter: Pay most for transportation. Live far away from city center. Most are male.
- Cluster 2 - Homemakers: Core transaction happens at grocery stores. Oldest group. Least expenditure, mobility, lower diversity of social network. Most are women.
- Cluster 3 - Youths: Core transactions are taxis. Youngest users. Most are explorers.
- Cluster 4 - Tech users: Core transactions are computer networks and information services. Young individuals. Higher than average expenditure and diversity of social contacts and mobility. Most are explorers.
- Cluster 6 - Dinners: Core transaction happens in restaurants. Middle-aged. High mobility and higher expenditures.
Advantages
- Comparing to TF-IDF, the selection of significant sequences discern the spending habits within the data. TF-IDF can’t uncover the shopping behavior of users.
- Comparing to LDA, our results are competitive and take account into temporal information within activities. LDA identified seven user groups and four of them are similar to our clusters.
- Identify similar but different spending patterns in different regions. e.g. In Puebla, six groups were detected and four of them are similar to those of Mexico City. Similar groups can be detected and compared across the world. Thus, it can serve as an government policy evaluation criteria of macroeconomic events such as inflation and employment.
- Proposed method can be applied to other similar Zipf-like distributions. e.g. disease codes in patients’ visits, law-breaking codes in police databases.
Author Octemull
LastMod 2019-01-19