chap 06 - 支持向量机 | Support Vector Machine (SVM)
Contents
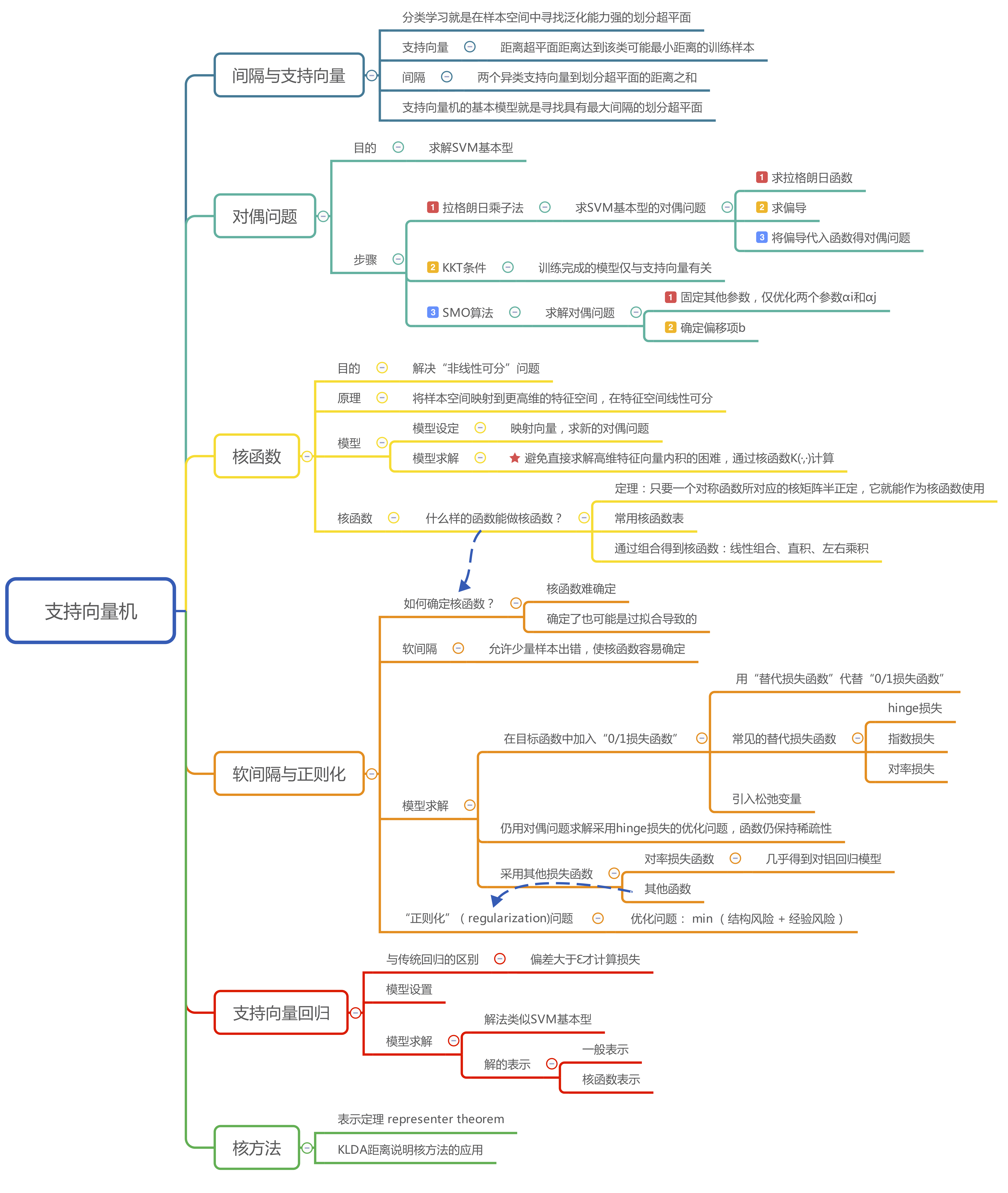
6.1 间隔与支持向量
划分:
给定训练样本集$D = {(x_1, y_1), (x_2, y_2), \cdots, (x_m,y_m)}, \, y_i \in {-1,+1}$,分类学习最基本的想法就是在样本集D所在的样本空间中寻找一个划分超平面,能将不同类别的样本划分开。
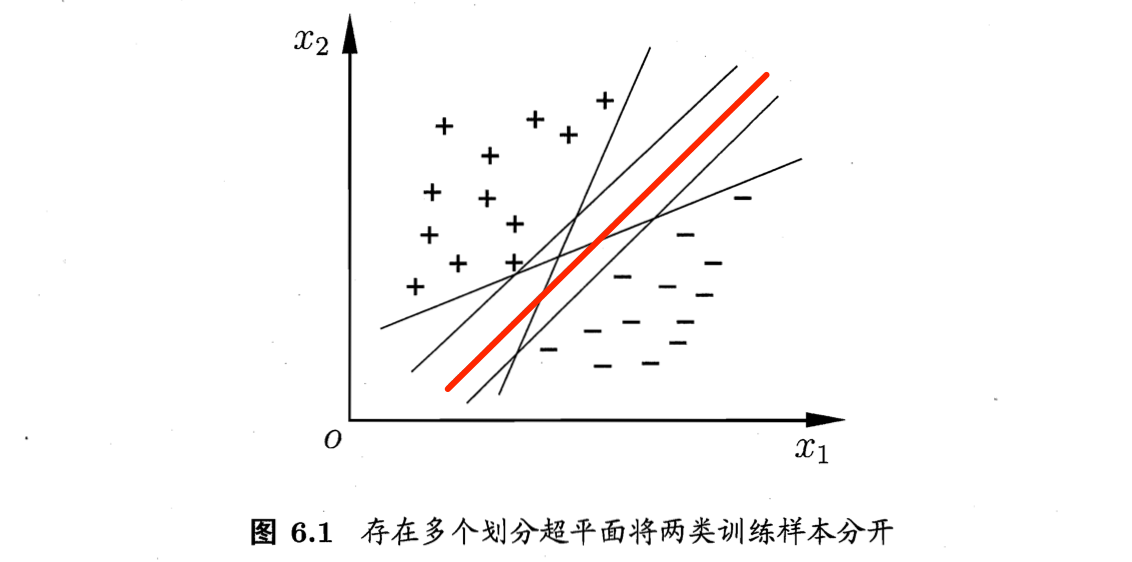
从图6.1中可以看出,存在多个划分超平面能将两类训练样本分开。那么那种最佳?直观上,我们会选择最中间的那个平面,因为:该划分平面对训练样本局部扰动的“容忍”最性好。(泛化能力最强)
举一个例子,由于训练集的局限性或噪声的因素,训练集外的样本可能比图6.1中的训练样本更接近两个类的分隔界,这将使许多划分超平面对新样本分类错误,而中间的红色超平面受影响最小。换言之,红色划分超平面产生的分类结果是最鲁棒(robust)的,对新样本的泛化能力最强。
用线性方程描述划分超平面
在样本空间中,划分超平面可通过如下线性方程来描述:
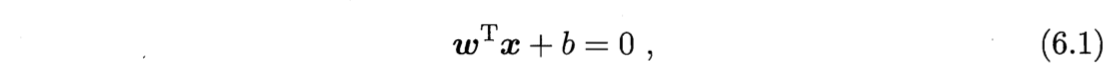 符号:
符号:
- 法向量:$\boldsymbol{w}=(w_1;w_2;\cdots,w_d)$,决定超平面的方向
- 位移项:$b$,决定超平面与原点之间的距离
- 超平面: 被法向量和位移决定,记做$(\boldsymbol{w}, b)$。
- 样本空间任意点x到超平面$(\boldsymbol{w}, b)$的距离:
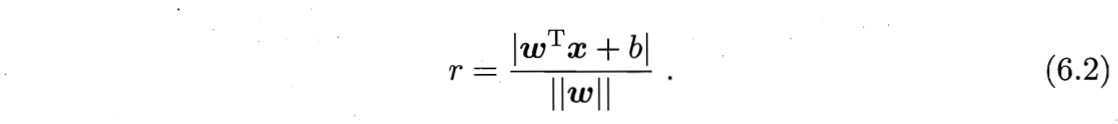
假设超平面$(\boldsymbol{w}, b)$能将训练样本正确分类,即对于$(x_i, y_i) \in D$,若$y_i=+1$,则有$\boldsymbol{w}^T \boldsymbol{x}_i +b > 0$;若$y_i=-1$,则有$\boldsymbol{w}^T \boldsymbol{x}_i +b < 0$。令
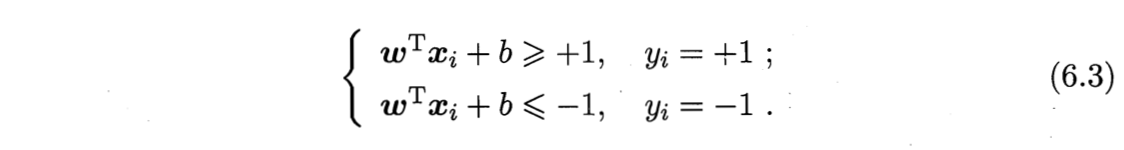
1️⃣支持向量 support vector:
如图6.2所示,距离超平面最近的这几个训练样本使(6.3)的等号成立,它们被称作“支持向量”。
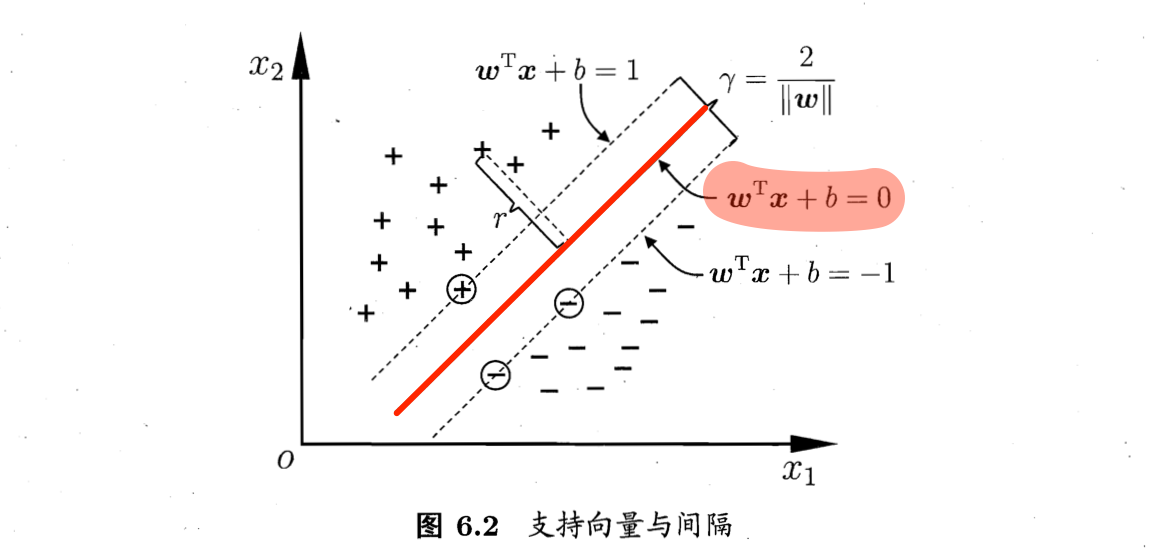
2️⃣间隔 margin:
两个异类支持向量到超平面的距离之和:
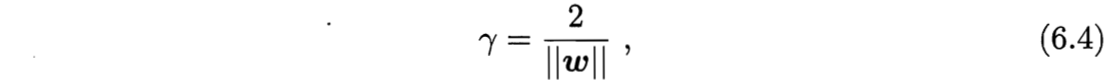
每个样本点对应一个特征向量。
3️⃣最大间隔( maximum margin )的划分超平面——SVM基本型:
找到满足式(6.3)中约束的参数$\boldsymbol{w}$和$b$,使得$\gamma$最大,即
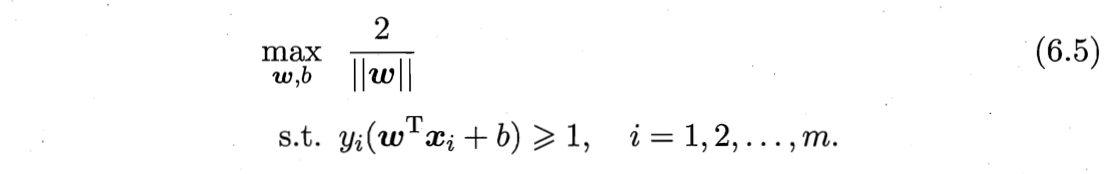
为了最大化间隔$\gamma$,仅需最大化$||\boldsymbol{w}||^{-1}$,等价于最小化$||\boldsymbol{w}||^2$。于是,上述最优化问题可重写为
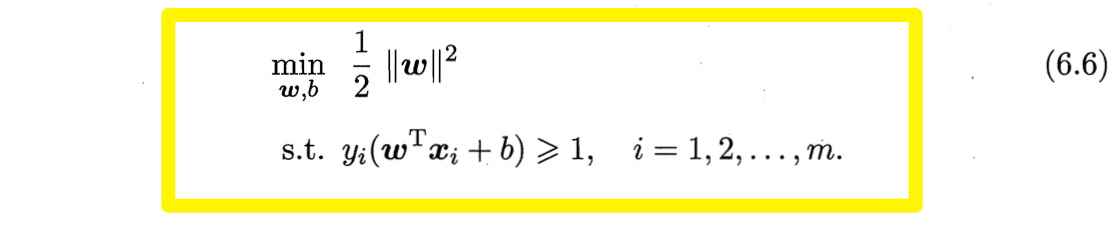 这就是支持向量机(Support Vector Machine, SVM)的基本型。
这就是支持向量机(Support Vector Machine, SVM)的基本型。
间隔貌似仅与w有关,但事实上b通过约束隐式地影响着w的取值,进而对间隔产生影响。
6.2 对偶问题 dual problem——SVM求解
求解式(6.6)可得最大间隔划分超平面所对应的模型
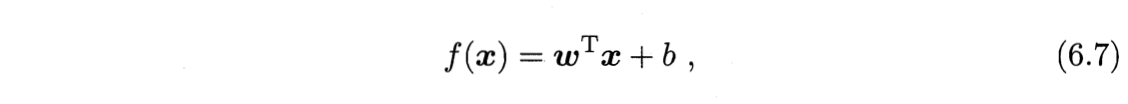
求解方法:
- ① 式(6.6)是一个凸二次规划问题,有现成的优化计算包求解,不予说明;
- ② 用拉格朗日乘子法求其“对偶问题”,则该问题的拉格朗日函数可写为
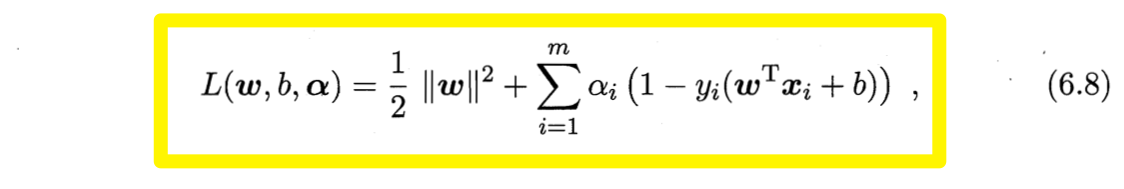
其中,$\boldsymbol{\alpha}=(\alpha_1; \alpha_2; \cdots; \alpha_m)$. 令$L(\boldsymbol{w},b,\boldsymbol{\alpha})$对$\boldsymbol{w}$和$b$的偏导为零可得
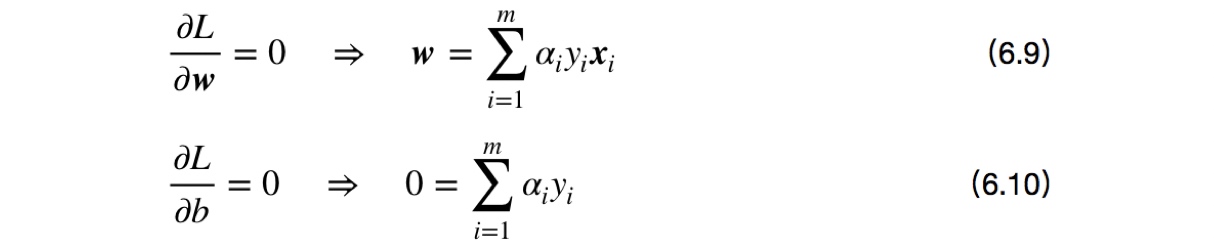
将式(6.9)带入(6.8),即可将中的w和b消去,再考虑式(6.10)的约束,就得到式(6.6)的对偶问题

消去w和b
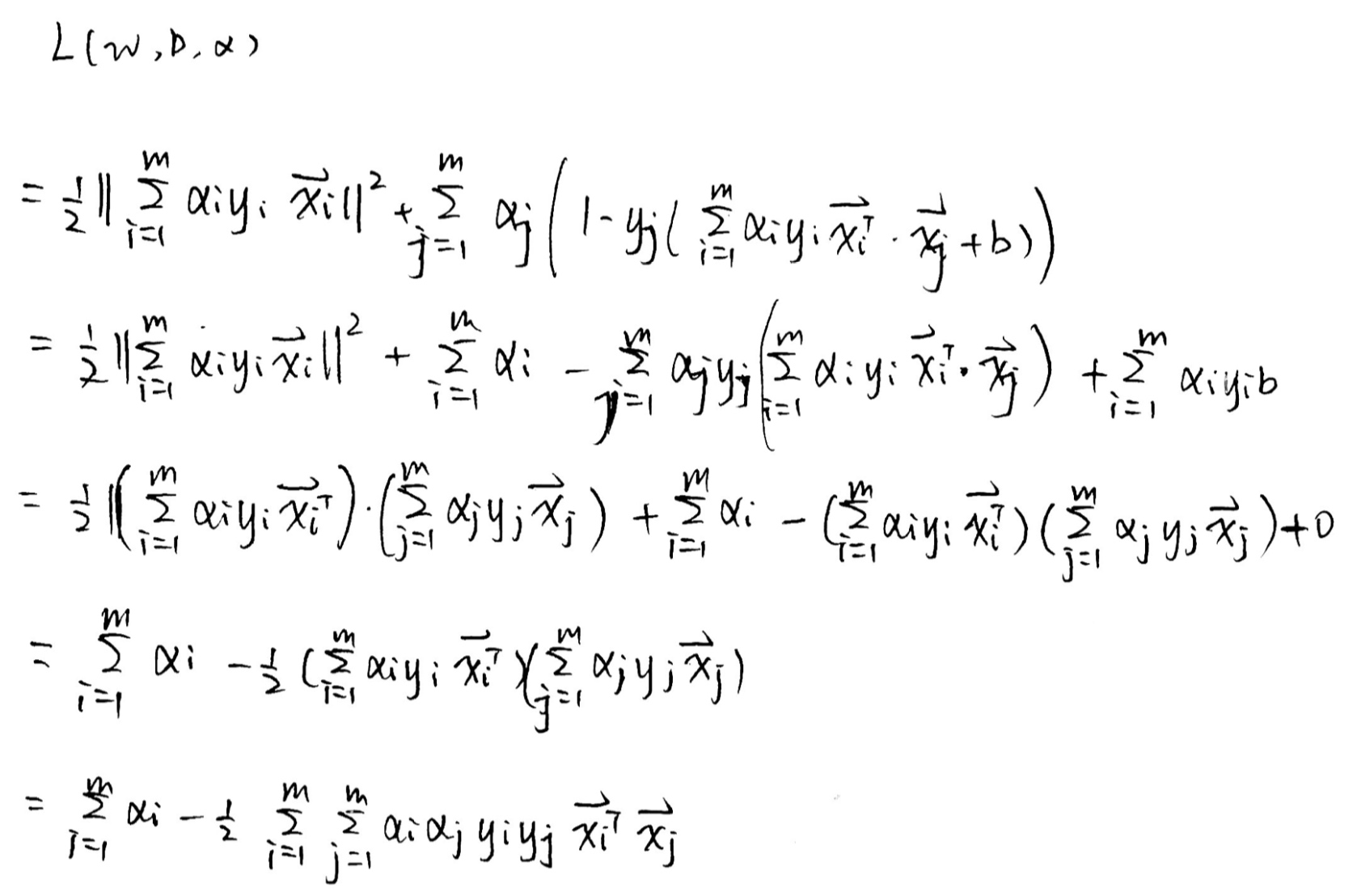
解出⍺后,求出w与b即可得到模型
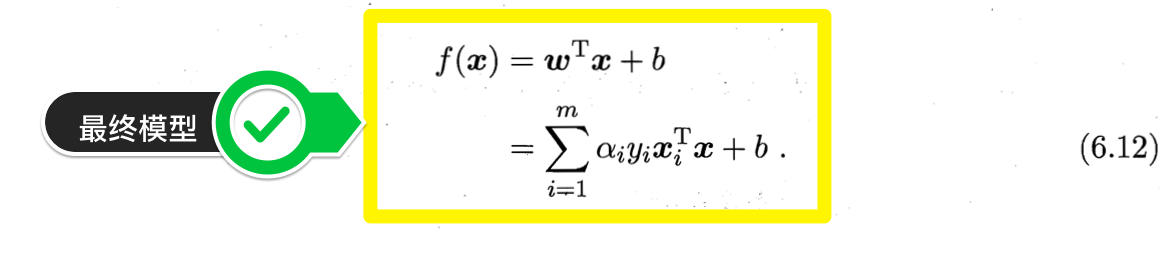
从对偶问题(6.11)解出的$⍺_i$是式(6.8)中的拉格朗日乘子,它恰对应着训练样本$(x_i,y_i)$。注意到式(6.6)中有不等式约束,因此上述过程需满足KKT(Karush-Kuhn-Tucker,库恩塔克)条件,即要求
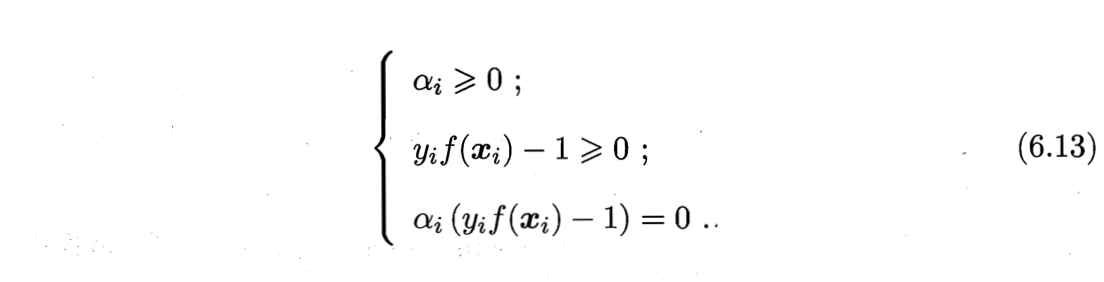
于是,对任意训练样本$(\boldsymbol{x}_i,y_i)$,总有$\alpha_i =0$或$y_i f(\boldsymbol{x}_i)=1$。
- 若$\alpha_i =0$,则该样本将不会在式(6.12)的求和中出现,也就不会对$f(x)$有任何影响;
- 若$\alpha_i >0$,则必有$y_i f(\boldsymbol{x}_i)=1$,所对应的样本点位于最大间隔的边界上,即该样本点是支持向量。
由此可见支持向量的重要性质:训练完成后,最终模型只与支持向量有关,与其他样本无关。
KTT条件

求解对偶问题的方法:
- ① 式(6.11)是一个二次规划问题,可使用通用的二次规划算法来求解(问题规模正比于训练样本数,实际任务开销大);
- ② 避免二次规划算法开销大的缺点,选用其他高效算法,如,SMO(Sequential Minimal Optimization)算法[Platt, 1988]。
SMO算法:
- 基本思路:先固定$\alpha_i$之外的所有参数,然后求αi上的极值。
(由于$\alpha_i, i=1,…,m$线性相关,固定$\alpha_i$之外的其他$\alpha$,则$\alpha_i$可由其他变量导出。于是,可以每次选择两个变量$\alpha_i$和$\alpha_j$,并固定其他参数)
- 步骤:
- 选取一对需要更新的变量αi和αj;
- 固定αi和αj以外的参数,求解式(6.11)获得更新后的αi和αj;
- 重复以上两步直至收敛。
注意: 只需选取的$\alpha_i$和$\alpha_j$中有一个不满足KKT条件,目标函数就会在迭代后增大[Osuna et al., 1997]。直观上看,KKT条件的违背程度越大,则变量更新后,可能导致的目标函数的增大幅度越大。
据此,SMO先取违背KKT条件程度最大的变量。第二个变量应选择使目标函数值增长速度最快的变量。但若要选择出最合适的变量,需要一一比较各变量的对应的目标函数的增幅大小,复杂度过高。
所以,SMO算法采用了一个启发式:使选取的两个变量所对应样本之间的间隔最大。 (一种直观解释:两个差异较大的变量与两个相似的变量相比,更新后会给目标函数值带来更大变化。)
SMO算法高效的原因:固定其他参数,只用优化两个参数。此过程可以做到高效。
1️⃣优化两个参数$\alpha_i$和$\alpha_j$的过程如下:
具体来说,仅考虑$\alpha_i$和$\alphaj$时,式(6.11)中的约束可重写为
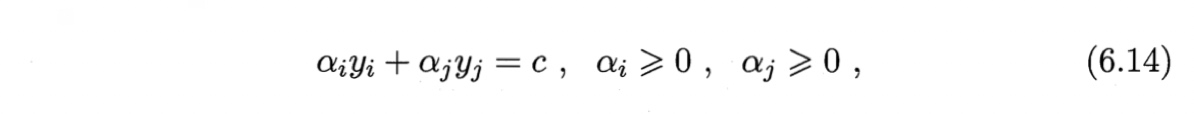 其中
其中
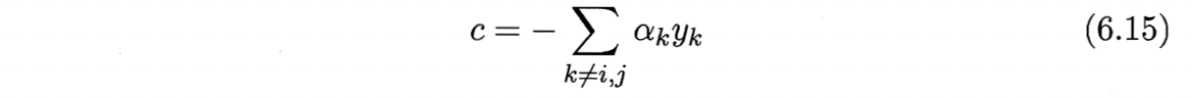 是使$\sum{i=1}^m \alpha_i y_i=0$成立的常数.用
是使$\sum{i=1}^m \alpha_i y_i=0$成立的常数.用
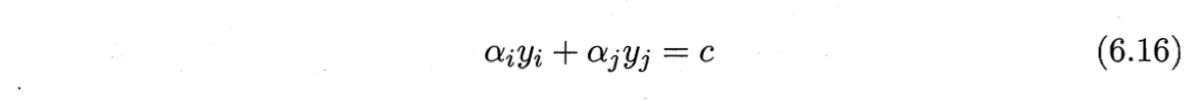 消去式(6.11)中的变量$\alpha_j$,则得到一个关于$\alpha_i$的单变量二次规划问题,仅有的$\alpha_i \geq 0$.不难发现,这样的二次规划问题具有闭式解,于是不必调用数值 优化算法即可高效地计算出更新后的$\alpha_i$和$\alpha_j$.
消去式(6.11)中的变量$\alpha_j$,则得到一个关于$\alpha_i$的单变量二次规划问题,仅有的$\alpha_i \geq 0$.不难发现,这样的二次规划问题具有闭式解,于是不必调用数值 优化算法即可高效地计算出更新后的$\alpha_i$和$\alpha_j$.
2️⃣确定偏移项b:
对任意支持向量$(\boldsymbol{x}_s,y_s)$都有$y_s f(\boldsymbol{x}_s)=1$(见式(6.13)),即
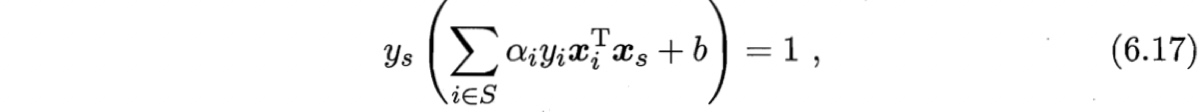
其中$S={i \, | \, \alpha_i>0, \, i=1,2,\cdots,m}$为所有支持向量的下标集.理论上,可选取任意支持向量并通过求解式(6.17)获得$b$,但现实任务中常采用一种更鲁棒的做法:**使用所有支持向量求解的平均值 **
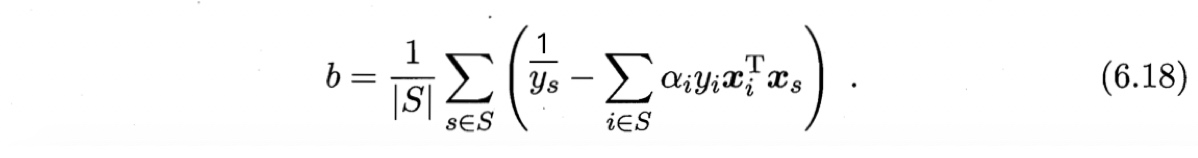
6.3 核函数 kernel function
- 前面的假设:训练样本是线性可分的,即存在一个超平面能将训练样本正确分类。
- 遇到的问题:现实任务重,不是所有问题都是线性可分的,可能找不到合适的超平面划分样本。如,“异或”问题就是非线性可分的。
- 解决方案: 将样本从原始空间映射到更高维的特征空间,使样本在新的空间线性可分。如图6.3所示。如果原始空间是有限维(属性个数有限),那么一定存在一个高维特征空间使样本可分。
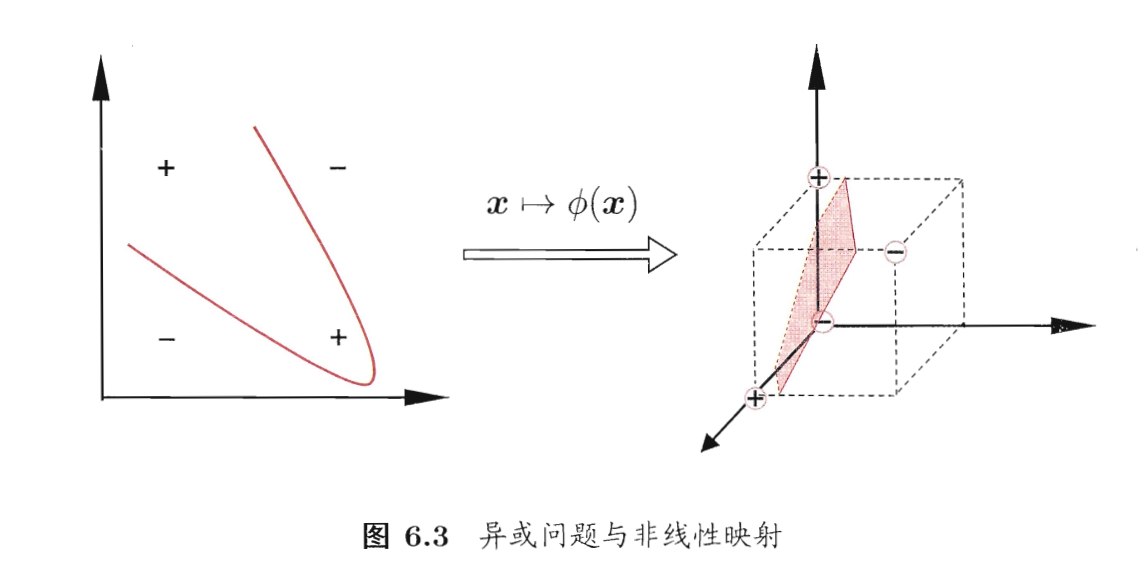
模型设定:
- 映射向量,求新的对偶问题。
令$\phi(\boldsymbol{x})$表示将$\boldsymbol{x}$映射后的特征向量,于是,在特征空间中划分超平面所对 应的模型可表示为
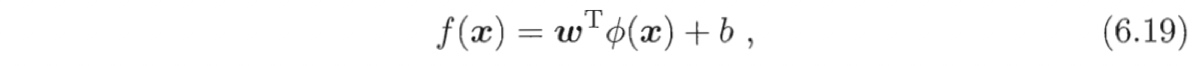
其中。和b是模型参数.类似式(6.6),有
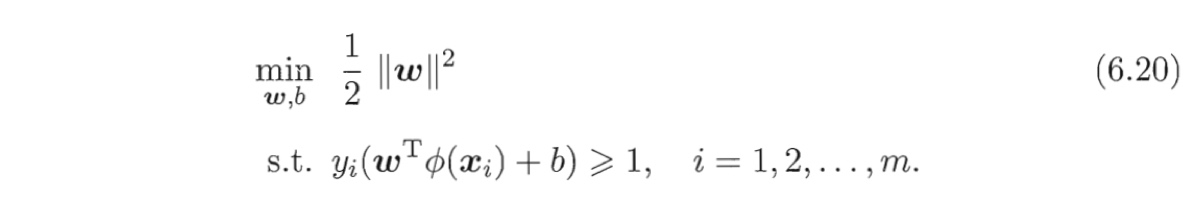
其对偶问题是

模型求解:
- 避免直接求解高维特征向量内积的困难,通过核函数$\kappa(\cdot, \cdot)$计算。
求解式(6.21)涉及到计算$\phi(\boldsymbol{x}_i)^T \phi(\boldsymbol{x}_j)$,这是样本$\boldsymbol{x}_i$与$\boldsymbol{x}_j$映射到特征空间之后的内积.由于特征空间维数可能很高,甚至可能是无穷维,因此直接计算$\phi(\boldsymbol{x}_i)^T \phi(\boldsymbol{x}_j)$通常是困难的.为了避开这个障碍,可以设想这样一个函数:
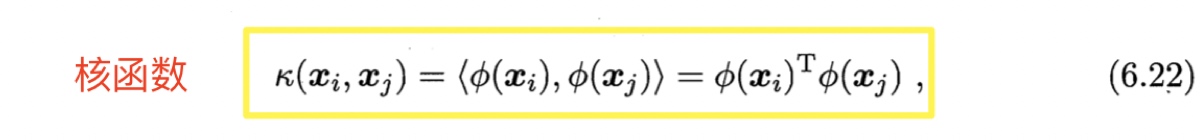 即$\boldsymbol{x}_i$与$\boldsymbol{x}_j$在特征空间的内积等于它们在原始样本空间中通过核函数$\kappa(\cdot, \cdot)$计算的结果。有了核函数,就省去了直接计算高维甚至无穷维特诊空间中的内积,于是式(6.21)可重写为
即$\boldsymbol{x}_i$与$\boldsymbol{x}_j$在特征空间的内积等于它们在原始样本空间中通过核函数$\kappa(\cdot, \cdot)$计算的结果。有了核函数,就省去了直接计算高维甚至无穷维特诊空间中的内积,于是式(6.21)可重写为
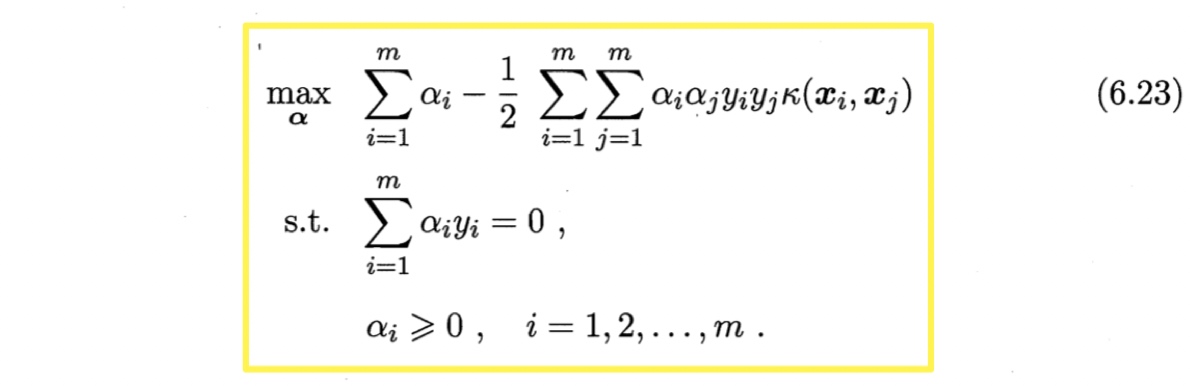 求解后可得
求解后可得

核函数 kernel function: 函数$\kappa(\cdot, \cdot)$,如
$$\kappa(\boldsymbol{x}_i,\boldsymbol{x}_j) = \langle \phi(\boldsymbol{x}_i), \phi(\boldsymbol{x}_j) \rangle = \phi(\boldsymbol{x}_i)^T \phi(\boldsymbol{x}_j)$$
支持向量展式 support vector expansion: 式(6.24),显示出模型最优解可通过训练样本的核函数展开。
已知映射,可写出核函数。但往往不知道映射。
1️⃣什么样的函数能做核函数?

- 以上定理表明,只要一个对称函数所对应的核矩阵半正定,它就能作为核函数使用。
- 事实上,对于一个半正定核函数,总能找到一个与之对应的映射φ。
- 换言之,任何一个核函数都隐式地定义了一个称为“再生核希尔伯特空间”(Reproducing Kernel Hilbert Space, RKHS)的特征空间。
常用核函数

通过组合得到核函数:线性组合、直积、左右乘积
- 若$\kappa_1$和$\kappa_2$为核函数,则对于任意$\gamma_1$和$\gamma_2$,两者的线性组合$\gamma_1 \kappa_1 + \gamma_2 \kappa_2$ 也是核函数;
- 若$\kappa_1$和$\kappa_2$为核函数,则两者的直积$\kappa_1 \bigotimes \kappa_2 (\boldsymbol{x}, \boldsymbol{z}) = \kappa_1(\boldsymbol{x}, \boldsymbol{z}) \kappa_2 (\boldsymbol{x}, \boldsymbol{z})$也是核函数;
- 若$\kappa_1$为核函数,则对于任意函数$g(\boldsymbol{x})$,$\kappa (\boldsymbol{x}, \boldsymbol{z}) = g(\boldsymbol{x}) \kappa_1(\boldsymbol{x}, \boldsymbol{z}) g(\boldsymbol{z})$也是核函数.
6.4 软间隔soft margin与正则化
2️⃣如何确定核函数?
问题:
- 现实中很难确定合适的核函数使样本在特征空间里线性可分。
- 即使找到,也很难断定貌似线性可分的结果是不是过拟合导致的。
缓解方法:引入“软间隔” soft margin,允许支持向量机在一些样本上出错。
硬间隔 hard margin:前面介绍的,要求所有样本均满足约束(6.3),即所有样本都必须被划分正确。
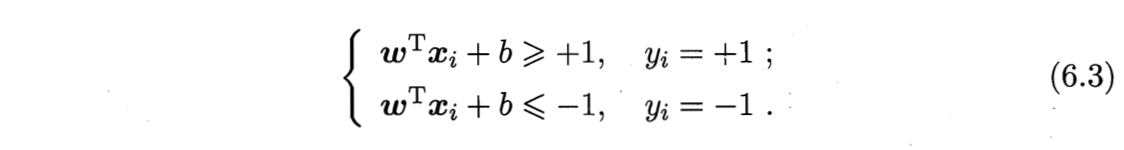
软间隔 soft margin:允许某些样本不满足约束
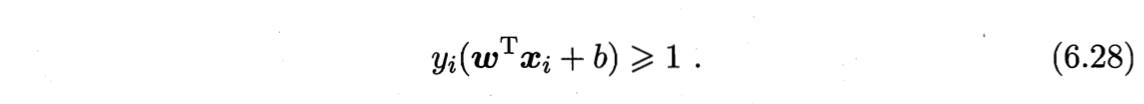
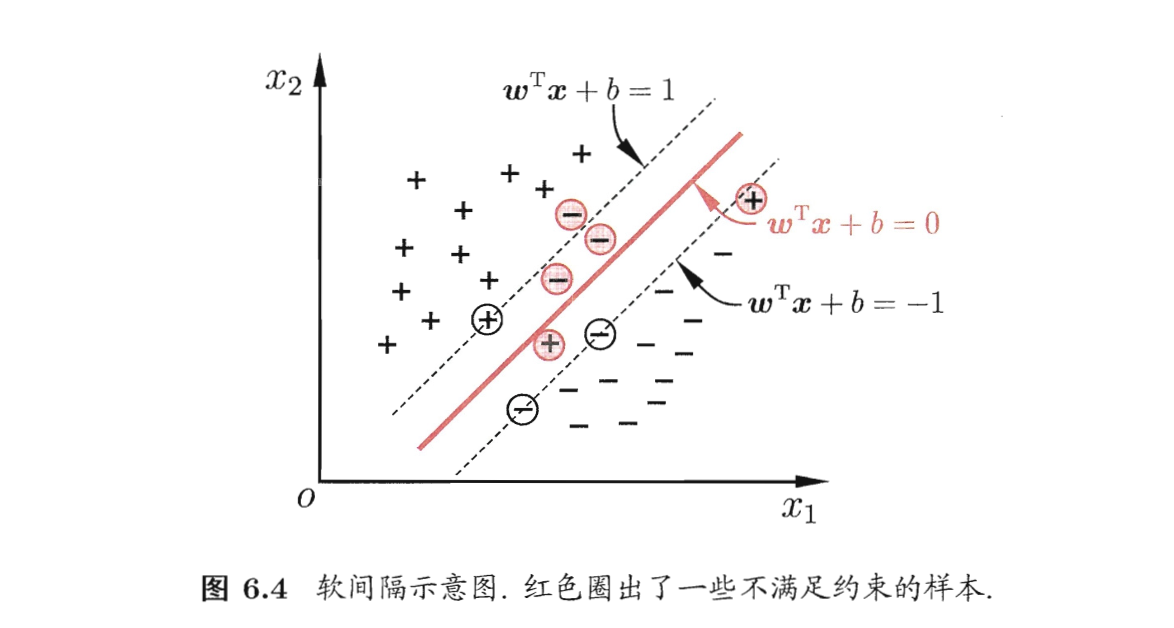
在最大化间隔时,不满足约束的样本应尽可能少。
优化的目标函数:
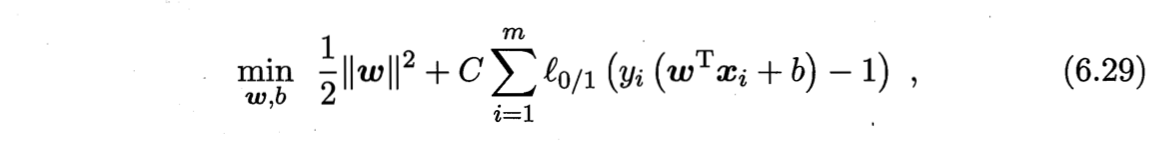
其中$C>0$是一个常数,$l_{0/1}$是“0/1损失函数”.
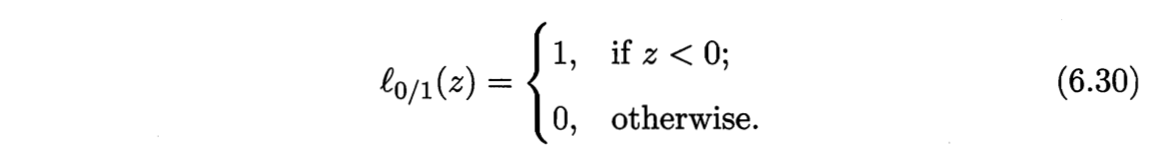
显然,当$C$为无穷大时,优化目标式(6.29)迫使所有样本满足约束式(6.28),此时优化目标式(6.29)等价于SVM基本型式(6.6);当C取有限值时,式(6.29)允许一些样本不满足约束。
替代损失函数:
问题: “0/1损失函数”非凸、非连续,数学性质不太好,使式(6.29)不易直接求解。
解决方法:
用“替代损失函数”代替“0/1损失函数”,它们通常是连续的凸函数,且为0/1损失函数的上界。
三种常用替代损失函数如下:
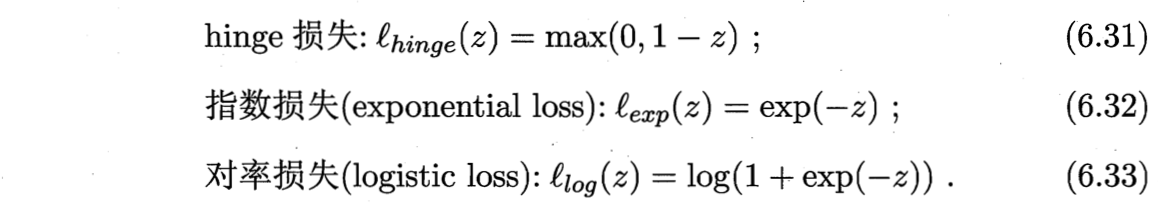
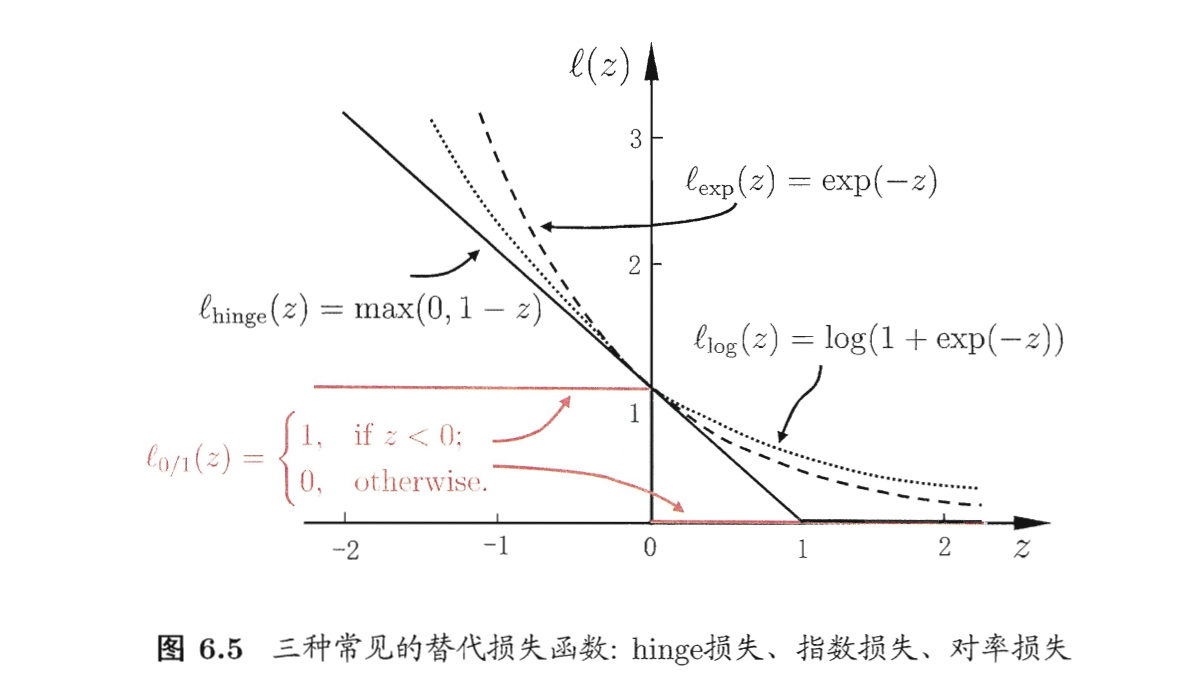
若采用hinge损失,则式(6.29)变成(以下均采用hinge损失推导)
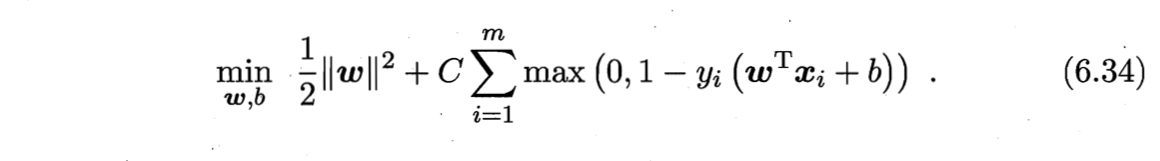
引入“松弛变量” (slack variables)$\xi_i \geq 0$ 可将式(6.23)重写为
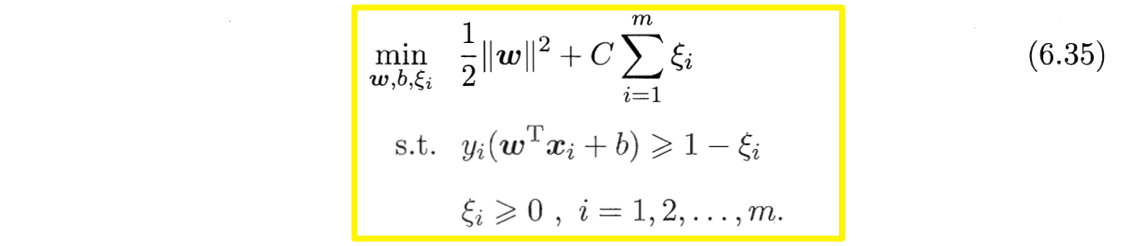
式(6.35)中每个样本都有一个对应的松弛变量,以表征该样本内不满足约束(6.28)的程度。
以上就是常用的“软间隔支持向量机”。
用拉格朗日乘子法求解式(6.35)的二次规划问题的对偶问题:
通过拉格朗日乘子法可得式(6.35)的拉格朗日常数
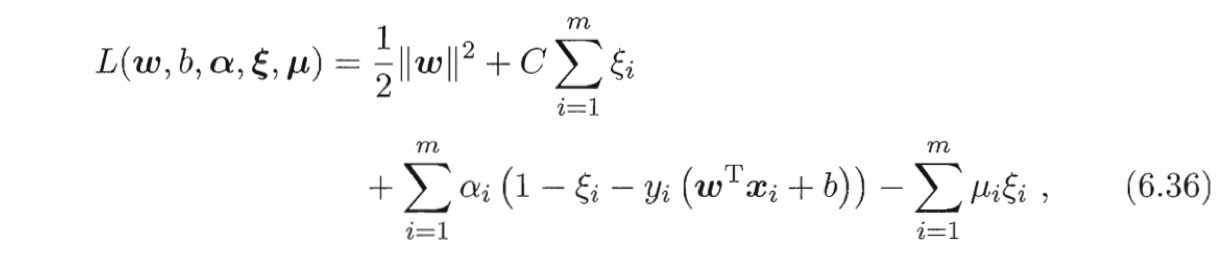 其中$\alpha_i \geq 0, \, \mu_i \geq 0$式拉格朗日乘子。
其中$\alpha_i \geq 0, \, \mu_i \geq 0$式拉格朗日乘子。
令$L$对$\boldsymbol{w},b,\xi_i$的偏导为0,可得
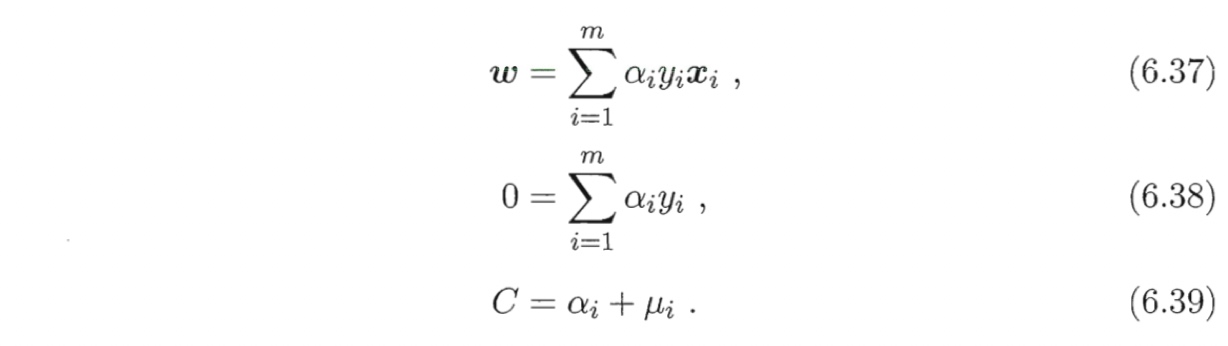 将式(6.37)-(6.39)代入式(6.36)即可得到式(6.35)的对偶问题
将式(6.37)-(6.39)代入式(6.36)即可得到式(6.35)的对偶问题

“软间隔”下的对偶问题(6.40)与“硬间隔”下的对偶问题(6.11)的唯一区别在于对偶变量的约束不同:前者是$0\leq \alpha_i \leq C$,后者是$0\leq \alpha_i$. 可采用6.2节中同样的SMO算法求解式(6.40);引入核函数后能得到与式(6.24)同样的支持向量展式。
类似式(6.13),对软间隔支持向量机,KKT条件要求
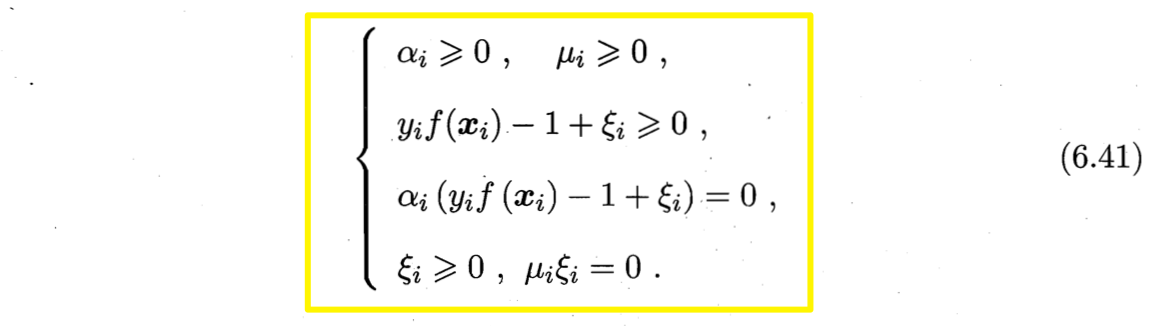
于是,对任意训练样本$(\boldsymbol{x}_i, y_i)$总有$\alpha_i=0$或$y_i f(\boldsymbol{x}_i) = 1-\xi_i$.
- 若$\alpha_i=0$, 则该样本不会对$f(x)$有任何影响;
- 若$\alpha_i > 0$,则必有即该样本是支持向量:
- 由式(6.39)$C=\alpha_i + \mu_i$可知,若$\alpha_i
- 若$\alpha_i =C$, 则有$\mu_i=0$, 此时若$\xi_i \leq 1$则该样本落在最大间隔内部(“不太严格的伪支持向量”),若$\xi_i > 1$则该样本被错误分类(“异类样本的不严格伪支持向量”)。
- 由式(6.39)$C=\alpha_i + \mu_i$可知,若$\alpha_i
由此可见,软间隔支持向量机的最终模型仍仅与支持向量有关,即通过采用hinge损失函数仍保持了稀疏性。
Q:采用除了hinge损失函数之外的其他函数?
A:① 如果使用对率损失函数$l_{\log}$来替代式(6.29)中的0/1损失函数,则几乎就得到了对率回归模型(3.27).
- 支持向量机与对率回归的优化目标相近,通常情形下它们的性能也相当.
- 对率回归的优势主要在于其输出具有自然的概率意义,即在给出预测标记的同时也给出了概率,而支持向量机的输出不具有概率意义,欲得到概率输出需进行特殊处理[Platt, 2000];
- 对率回归能直接用于多分类任务,支持向量机为此则需进行推广[Hsu and Lin,2002].
- 从图6.5可看出,hinge损失有一块“平坦”的零区域,这使得支持向量机的解具有稀疏性,而对率损失是光滑的单调递减函数,不能导出类似支持向量的概念,因此对率回归的解依赖于更多的训练样本,其预测开销更大.
②采用别的替代损失函数以得到其他学习模型——“正则化”(regularization)问题
- 这些模型的性质与所用的替代函数直接相关,但它们具有一个共性:优化目标中的第一项用来描述划分超平面的“间隔”大小,另一项$\sum_{i=1}^m l(f(\boldsymbol{x}_i), y_i)$用来表述训练集上的误差,可写为更一般的形式
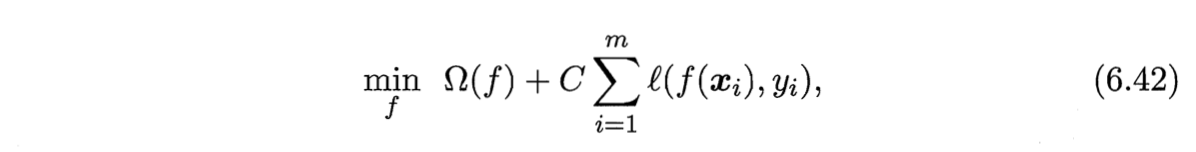
其中$\Omega (f)$称为“结构风险”(structural risk),用于描述模型$f$的某些性质;第二项$\sum_{i=1}^m l(f(\boldsymbol{x}_i), y_i)$称为“经验风险”(empirical risk),用于描述模型与训练数据的契合程度;C用于对二者进行折中(设置权重大小).
传统意义上的”结构风险”是指引入模型结构因素后的总体风险(或许更宜译为”带结构风险”), 本书则是指总体风险中直接对应于模型结构因素的部分, 这样从字面上更直观, 或有助于理解其与机器学习中其他内容间的联系. 参见p.160.
- 从经验风险最小化的角度来看,$\Omega (f)$表述了我们希望获得具有何种性质的模型(例如希望获得复杂度较小的模型),这为引入领域知识和用户意图提供了途径;
- 另一方面,该信息有助于削减假设空间,从而降低了最小化训练误差的过拟合风险.
从这个角度来说,式(6.42)称为“正则化”(regularization)问题,$\Omega (f)$称为正则化项,$C$则称为正则化常数.
$L_p$范数(norm)是常用的正则化项,其中$L2$范数$||\boldsymbol{w}||_2$倾向于$\boldsymbol{w}$的分量取值尽量均衡,即非零分量个数尽量稠密,而$L0$范数和$L1$范数则倾于$\boldsymbol{w}$的分量尽量稀疏,即非零分量个数尽量少.
6.5 支持向量回归 Support Vector Regression, SVR
目的: 给定回归样本$D = {(x_1, y_1), (x_2, y_2), \cdots, (x_m,y_m)}, \, y_i \in \mathbb{R}$习得一个形如$f(\boldsymbol{x})=\boldsymbol{w}^T \boldsymbol{x} +b$(6.7)的回归模型,使$f(x)$与$y$尽量接近。
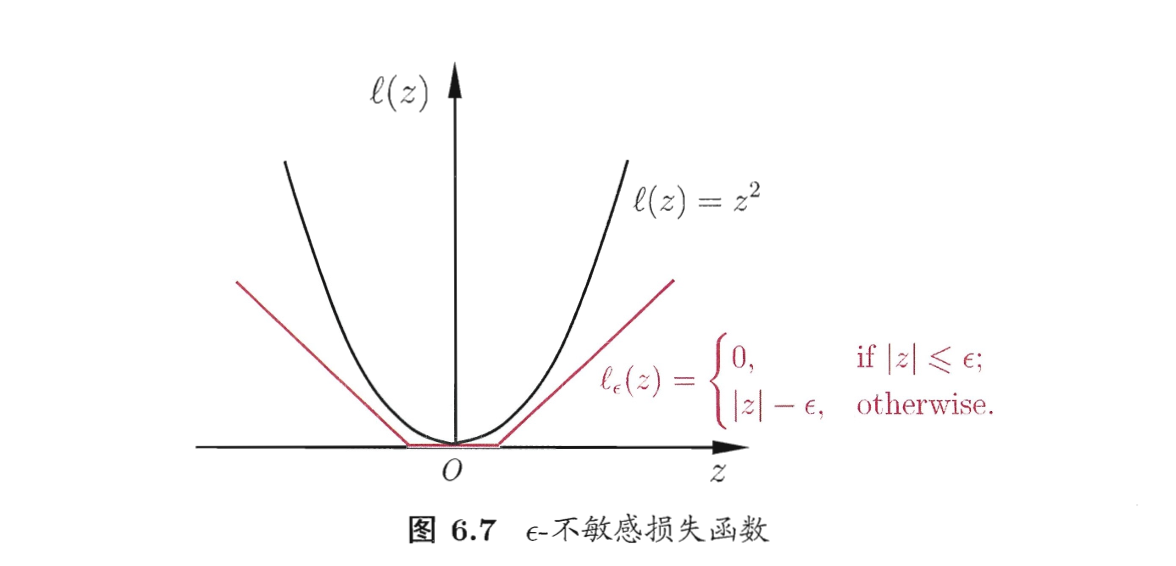
与传统回归的区别:允许$f(x)$与$y$之间最多有$\epsilon$的偏差,大于$\epsilon$才计算损失。而不是只要$f(x)$与$y$不等就计算损失。如图6.6,相当于把预测正确的范围从一条线扩展成一个宽度为$2 \epsilon$的间隔带。
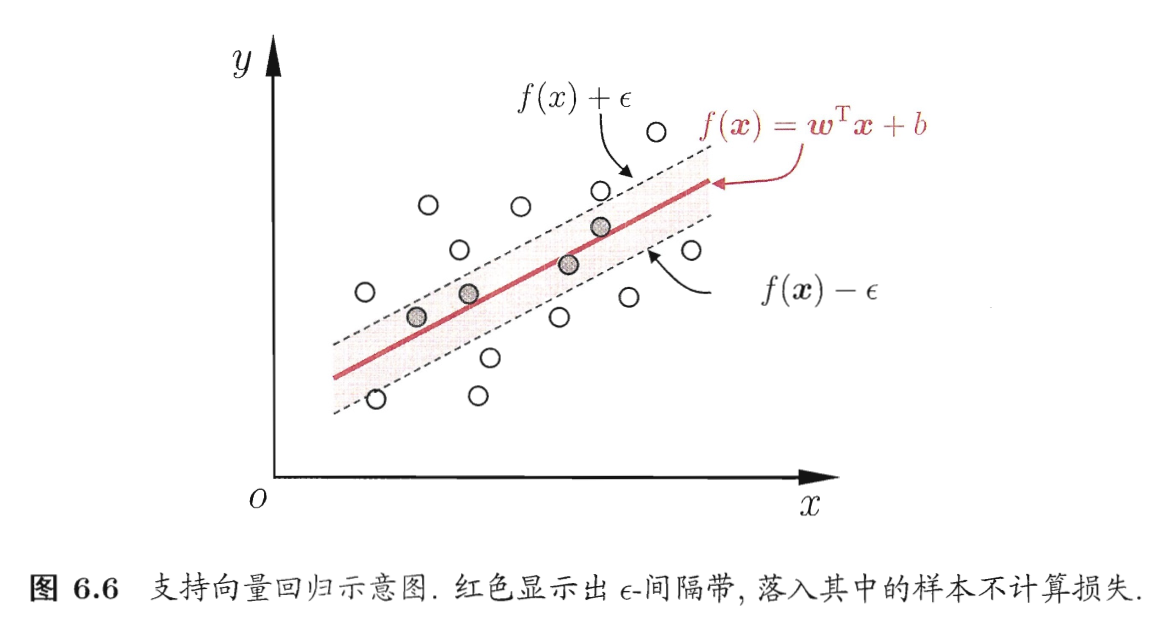
SVR模型:
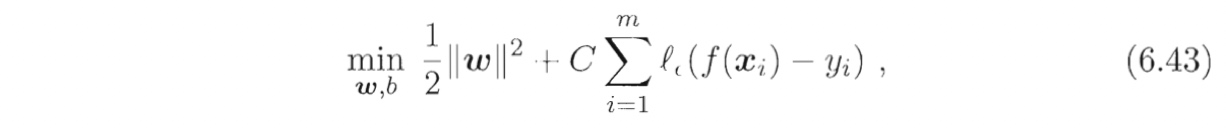 其中$C$为正则化常数,$l_c$是图6.7所示的$\epsilon -$不敏感损失($\epsilon$-insensitive loss)函数
其中$C$为正则化常数,$l_c$是图6.7所示的$\epsilon -$不敏感损失($\epsilon$-insensitive loss)函数
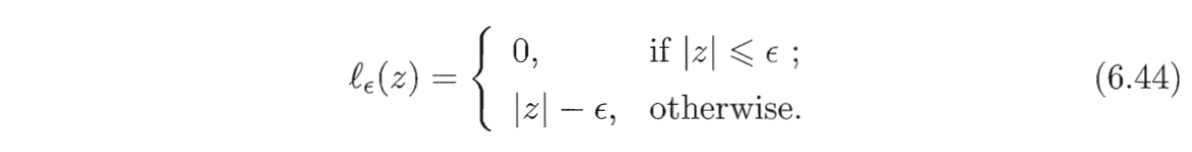
 引入松弛变量$\xi_i$和$\hat{\xi}_i$(间隔带两侧的松弛程度可以不同),式(6.43)可重写为
引入松弛变量$\xi_i$和$\hat{\xi}_i$(间隔带两侧的松弛程度可以不同),式(6.43)可重写为
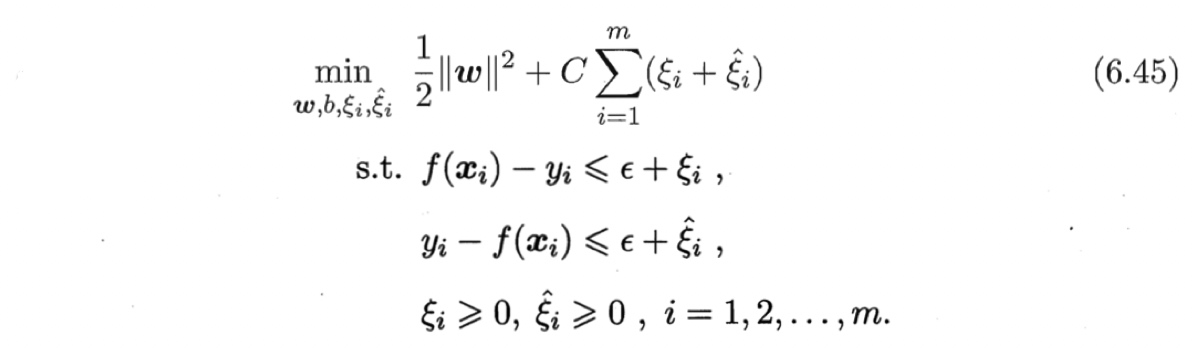
求解SVR问题:
- 拉格朗日乘子法
- 对偶问题
- KKT条件
类似(6.36),通过引入拉格朗日乘子$\mu_i \geq 0,\ \bar{\mu}_i \geq 0,\ \alpha_i \geq 0,\ \hat{\alpha}_i \geq 0,$由拉格朗日乘子法可得式(6.45)的拉格朗日函数
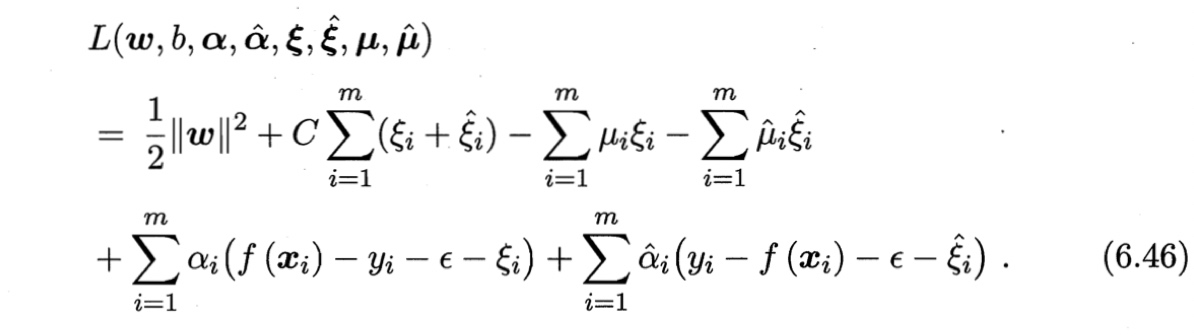 代入式(6.7),再令$L$对$\boldsymbol{w},\ b,\ \xi_i,\, \bar{\xi}_i$的偏导为0,得
代入式(6.7),再令$L$对$\boldsymbol{w},\ b,\ \xi_i,\, \bar{\xi}_i$的偏导为0,得
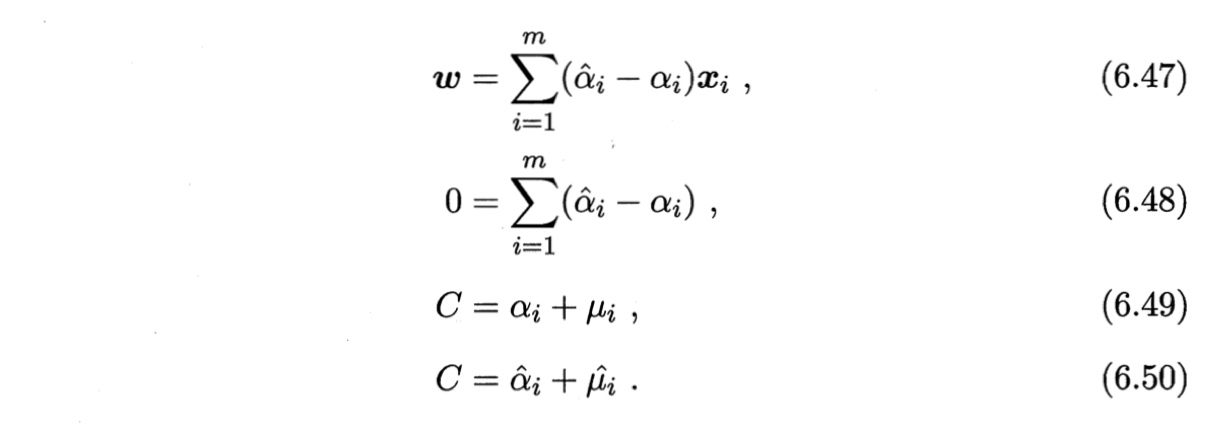 将式(6.47)-(6.50)代入式(6.46),可得SVR对偶问题
将式(6.47)-(6.50)代入式(6.46),可得SVR对偶问题
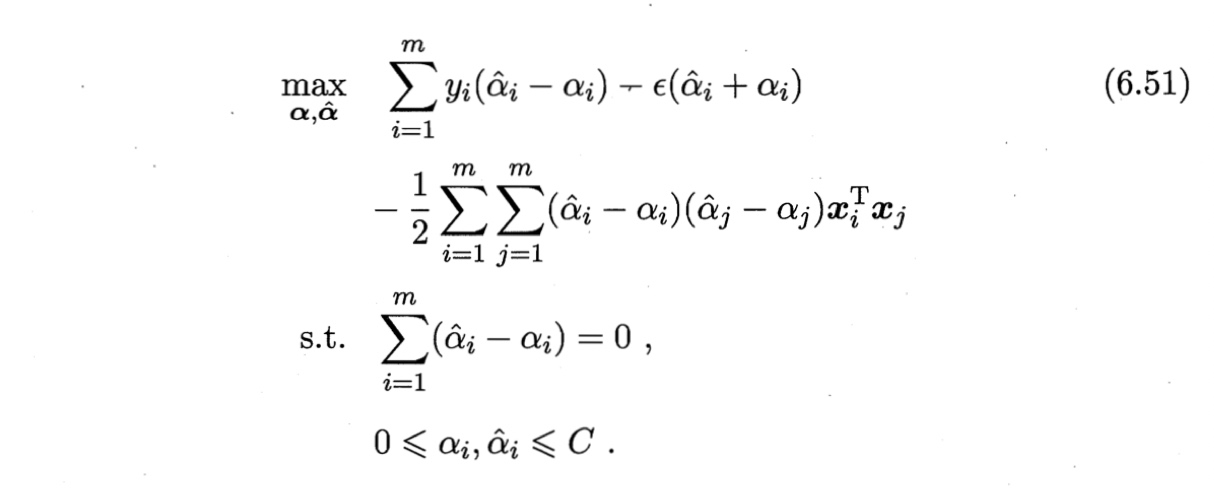 上述过程需满足KTT条件,即
上述过程需满足KTT条件,即
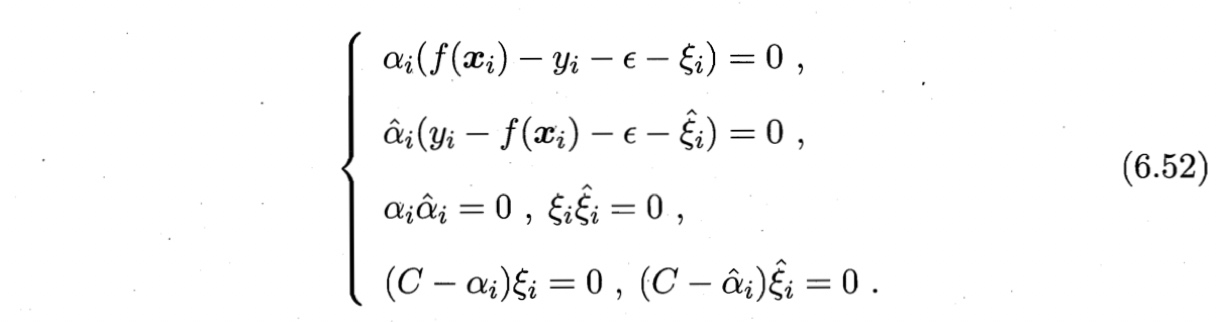
可以看出: * 当且仅当时$f(\boldsymbol{x}_i) - y_i -\epsilon -\xi_i=0$,$⍺_i$能取非零值;当且仅当$ y_i - f(\boldsymbol{x}_i)-\epsilon -\hat{\xi}_i=0$时,$\hat{\alpha}_i$能取非零值(仅当样本$(\boldsymbol{x}_i, y_i)$不落入$\epsilon$-间隔带中,相应的$\alpha_i$和$\hat{\alpha}_i$才能取非零值。) * 约束$f(\boldsymbol{x}_i) - y_i -\epsilon -\xi_i=0$和$ y_i - f(\boldsymbol{x}_i)-\epsilon -\hat{\xi}_i=0$不能同时成立(样本不能同时落入$\epsilon$-间隔带外的上方和$\epsilon$-间隔带外的下方),因此$\alpha_i$和$\hat{\alpha}_i$中至少有一个为零。
SVR的解:
一般表示:将式(6.47)带入(6.7)可得
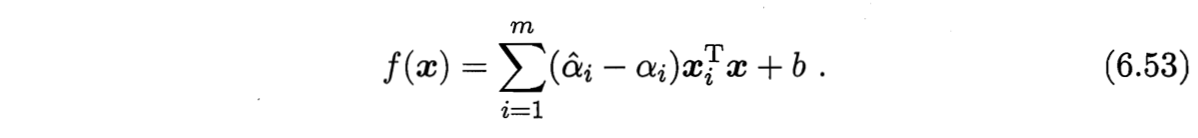
- 稀疏性:SVR的支持向量才对上式(6.53)有贡献。能使式(6.53)中的$(\hat{\alpha}_i - \alpha_i) \neq 0$的样本即为SVR的支持向量,必落在$\epsilon$-间隔带之外。
- 参数求解:
由KKT条件,对每个样本都有$(C - \alpha_i) \xi_i = 0$且$\alpha_i(f(\boldsymbol{x}_i) - y_i -\epsilon -\xi_i=0$
- $\alpha_i$:求解式(5.5.1)得到$\alpha_i$;
- $b$:若$0< \alpha_i <C$,则必有$\xi_i = 0$进而求得$b$,如下
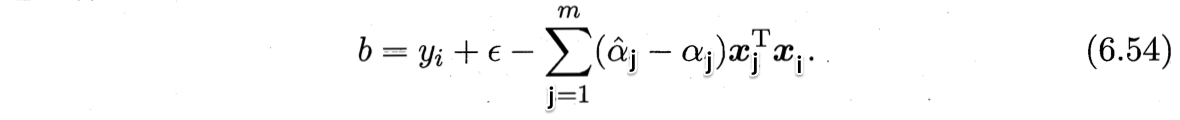
理论上,任取满足$0< \alpha_i <C$的样本求b即可。现实中常采用更鲁棒的方法:选取多个(或所有)满足条件$0< \alpha_i <C$的样本求解b后取平均值
求解式(5.5.1)得到$\alpha_i$;
$\boldsymbol{w}$:若考虑特征映射形式(6.19),则相应的,式(6.47)将形如
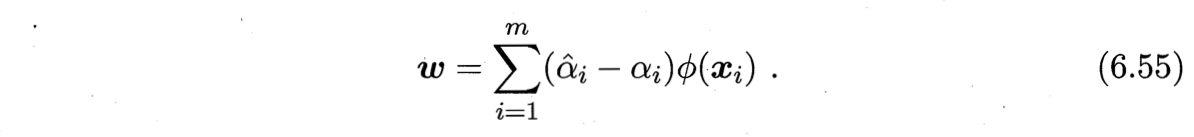
核函数表示:
将式(6.55)代入(6.19),则SVR可表示为
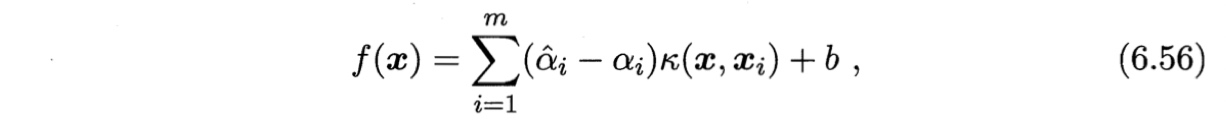 其中$\kappa(\boldsymbol{x}_i, \boldsymbol{x}_j) = \phi(\boldsymbol{x}_i)^T \phi(\boldsymbol{x}_j)$为核函数。
其中$\kappa(\boldsymbol{x}_i, \boldsymbol{x}_j) = \phi(\boldsymbol{x}_i)^T \phi(\boldsymbol{x}_j)$为核函数。
6.6 核方法
回顾式(6.24)和(6.56)可发现,给定训练样本${(x_1, y_1), (x_2, y_2), \cdots, (x_m,y_m)}\$,若不考虑偏移项b,则无论SVM还是SVR,学得的模型总能表示成核函数$\kappa(\boldsymbol{x}, \boldsymbol{x}_i) $的线性组合。
表示定理 representer theorem:

证明参阅[Schölkopf and Smola, 2002]。其中用到了关于实对称矩阵正定性充要条件的Mercer定理。
解释:
- 表示定理对损失函数没有限制,对正则化项Ω仅要求单调递增,甚至不要求Ω是凸函数;
- 意味着,对于一般的损失函数和正则化项,优化问题(6.57)的最优解$h^*(\boldsymbol{x})$都可以表示为核函数$\kappa(\boldsymbol{x}, \boldsymbol{x}_i)$的线性组合。
- 核函数有巨大威力。
核方法 Kernel methods:
- 一系列基于核函数的学习方法
- 最常见的是用过“核化”(即引入核函数)来将线性学习器拓展为非线性学习器。
举一个例子🌰:
线性判别分析 LDA → 核线性判别分析 (Kernelized Linear Discriminant Analysis, KLDA)
步骤抽象:
- 将样本映射(𝜙)到特征空间𝔽;
- 在𝔽中执行LDA(类似推导出特征空间样本的LDA学习过程);
- 应用“表示定理”:
- 映射表达难知道,用核函数$\kappa(\boldsymbol{x}, \boldsymbol{x}_i) = \phi(\boldsymbol{x})^T \phi(\boldsymbol{x}_i) $隐式表达映射𝜙和特征空间𝔽;
- 表示出𝛺和损失函数𝑙;
- 表示出h(x);
- 表示出w;
- 重写KLDA的学习目标,用LDA法求解即可。
我们先假设可通过某种映射$\phi: \cal{X} \mapsto \mathbb{F} $将样本映射到一个特征空间$\mathbb{F}$,然后在$\mathbb{F}$中执行线性判别分析,以求得
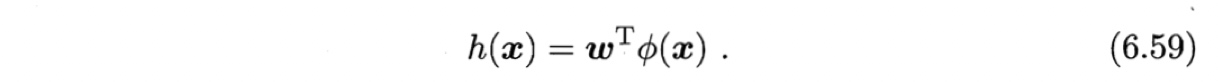
类似于式(3.35), KLDA的学习目标是
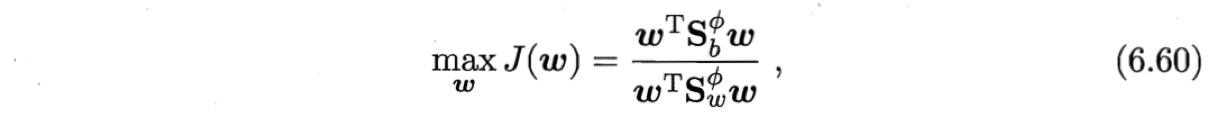
其中$S_b^{\phi}$和$S_w^{\phi}$分别为训练样本在特征空间$\mathbb{F}$中的类间散度矩阵和类内散度矩阵.令$X_i$表示第$i \in {O,1}$类样本的集合,其样本数为$m_i$;总样本数$m=m_0 + m_1$.第$i$类样本在特征空间$\mathbb{F}$中的均值为
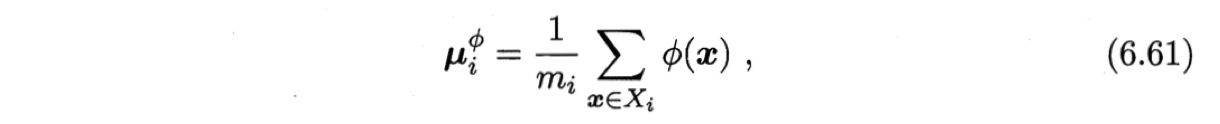
两个散度矩阵分别为
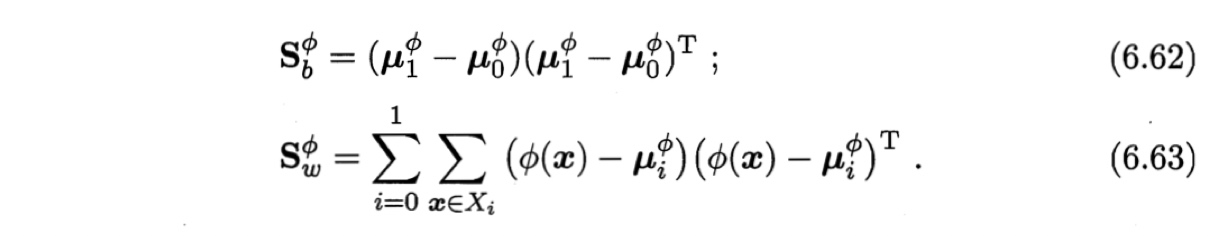
通常我们难以知道映射$\phi$的具体形式,因此使用核函数$\kappa(\boldsymbol{x}, \boldsymbol{x}_i) = \phi(\boldsymbol{x})^T \phi(\boldsymbol{x}_i) $$\kappa(\boldsymbol{x}, \boldsymbol{x}_i) = \phi(\boldsymbol{x})^T \phi(\boldsymbol{x}_i) $来隐式地表达这个映射和特征空间$\mathbb{F}$.把$J(w)$作为式(6.57)中的损失函数$l$,再令$\Omega \equiv 0$,由表示定理,函数$h(x)$可写为
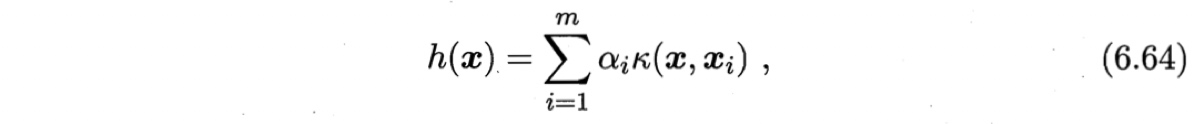 于是由式(6.59)可得
于是由式(6.59)可得
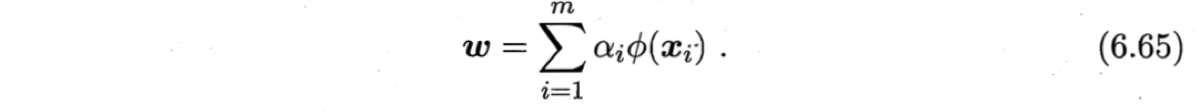
令$K \in \mathbb{R}^{m \times m}$为核函数$\kappa$所对应的核矩阵,$(K)_{ij}= \kappa(\boldsymbol{x}, \boldsymbol{x}_i) $.令$\boldsymbol{1}_i \in {1,0}^{m \times 1}$为第$i$类样本的指示向量,即$\boldsymbol{1}_i$的第$j$个分量为$1$当且仅当$\boldsymbol{x}_j \in X_i$, 否则$\boldsymbol{1}_i$的第$j$个分量为0.再令
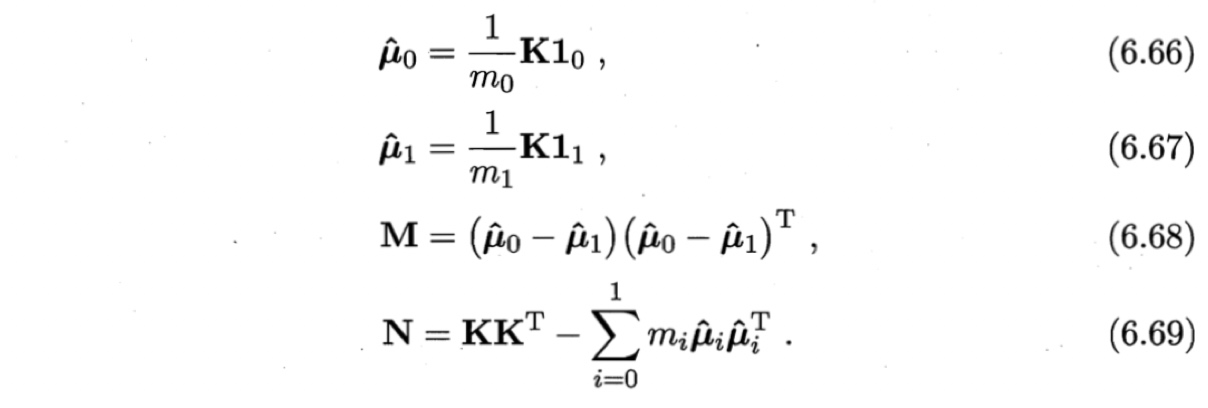
于是,式(6.60)等价为
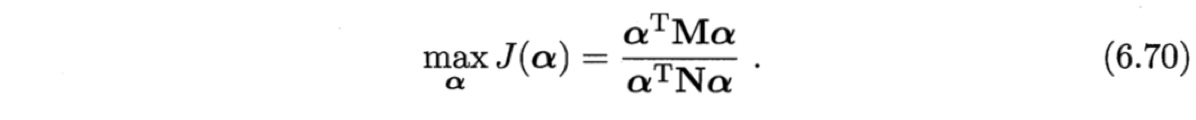
显然,使用线性判别分析求解方法即可得到$\boldsymbol{\alpha}$,进而可由式(6.64)得到投影函数$h(\boldsymbol{x})$.
Author Octemull
LastMod 2019-03-23